第1章绪论
1.1课题研究的背景及意义
随着当代数字医疗设备的不断发展,医学图像诊断技术在当今医疗事业中扮演的角色越来越重要,现代医疗诊断技术已经离不开医学图像信息了。医学图像不仅应用于临床诊断,而且在科学研究等领域发挥着重要的作用,大量医学设备的普及,例如数字化摄影 DR (Digital Radiography, DR)、多层螺旋断层扫描 MSCT (muti-slice Computed omography, MSCT)、磁共振成像 MRJ (Magnetic Resonance Imaging, MRI)、IH电子发射型计算机断层-计算机X线断层扫描PET-CT (Position Emission Tomography-Computed Tomography, PET-CT),各种成像手段也被越来越多的运用到医学检查中,这就使获得的图像数据量正在迅速的增长目前各大医院普遍使用PACS (Picture Archiving and Communication System ),即医学影像存档与通信系统对海量的医学图像信息进行管理,它是由计算机与网络通讯设备完成对医学影像资料的获取、显示、存储、传送和管理等,从而实现了对医学影像的数字化处理技术,是计算机网络技术与影像处理技术在医学技术高度发展的产物[4]。它的出现很大程度上解决了模拟医学影像的采集以及对其进行数字化处理、医学影像图像的存储以及管理、数字化医学影像的快速传递、影像的数字化处理以及重现、医院信息化系统集成以及影像信息共享等六个方面[5],但是随着图像信息量的迅速膨胀、患者对医学诊断水平以及用户需求的不断增加,传统的PACS系统也开始暴露自身的缺点:建设费用高,例如对于一个大型的三甲医院它每年的图像数量就能达到TB级甚至数十TB,这样区域内的数据量将会达到PB级,如果采用传统存储区域网络FC SAN (光纤存储区域网络)构建PB级容量的存储系统的话,建设费用是很高的;还有就是性能和扩展能力差,即使我们采用FCSAN,也很难满足PB级的数据的传输和处理[6]。因此我们需要寻求更好的方法来解决以上的问题和更好的平台来存储和处理日益增长的医学影像数据。
……….
1.2国内外发展现状
2006年,谷歌首先提出了云计算技术,就立刻引发了世界云技术的浪潮,很多国际性公司开始加入对这项技术的研究,例如亚马逊,、微软等国际跨国公司。在云计算技术中,开放式编程平台是云计算技术的精髓,普通的用户可以和专家一样用它去编写程序[8],云计算技术软件的这种开源性特点让用户可以获取和完善代码,这也是云计算能快速发展的原因。其中云计算技术包括分布式计算处理技术、并行计算处理技术以及网格计算处理技术,这些技术都引领着互联网新的发展趋势,相信在未来的理论研究以及其它方面的应用上,云计算技术的发展是不可限量的。根据埃森哲咨询公司提供的报告,在国内使用云计算技术的用户数量要大大低于国外,其主要原因就是中国企业比较担心云计算的安全性,不过相比公有云的建设,国内的大多数企业对私有云建设还是比较热衷的。,云计算的创新,在全国还吸引了许多的大型电信公司,比如中国移动公司推出的Big Cloud云计算平台,中国电信公司的E云计划平台以及中国联通构建的互联云等等,在云计算平台的基础上,各大通信运营商都依次开发了许多相关的软件服务,并且搭建了规模比较大的云计算实验的平台,主要用于研究数据挖掘,云存储和大数据搜索引擎等方面[8]。因此我相信在不久的将来,在云计算供应商的帮助下,云计算在我国将迅猛发展,逐渐从早期研究阶段发展到成熟阶段,云计算在国内的水平也会大大的提高,越来越多的国内大型企业将会加入到云计算的研究当中。
………..
第2章相关工作
2.1 Hadoop分布式平台
Hadoop[i9]是一个分布式计算框架,它是由Apache开源组织提出的,具有高可用性、高可扩展性和高容错性的特点,可以运行在廉价的PC建立的分布式集群上。Hadoop主要由Hadoop分布式文件系统HDFS和MapReduce分布式计算模型组成,还有一些其它的子项目,例如,HBase,Hive,Pig, ZooKeeper等等。其中HBase与谷歌的BigTable有很多相似的地方,它是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统;Zookeeper是Google的Chubby—个幵源的实现,是一个大型的开放源码的分布式应用程序协调服务;Hive是一个数据仓库工具,它定义了一个类似于SQL的查询语言HQL,能够将用户编写的SQL语句转化为相应的MapReduce程序签于Hadoop执行;Pig就是一个处理海量数据集的脚本语言,提供类似SQL的脚本语言,Hadoop的技术栈如图2-1。作为Hadoop最为出名的HDFS系统和MapReduce计算模型,其中HDFS分布式文件系统在Hadoop的底层,可以被看作是Hadoop的基础架构,主要用来存储集群中存在的所有存储节点上的文件,它是GFS (Google File System)的幵源版本,能够提供高吞吐量的数据访问,非常适合存储海量PB级的大文件;Hadoop的上层是MapReduce引擎,它由JobTrackers和TaskTrackers组成,两者之间的关系。
……………
2.2 DICOM 标准
DICOM 是 Digital Imaging and Communications in Medicine 的简称,它主要包括医学数字成像和通信两个方面,是由美国放射学会和国家电器制造商协会共同制定的,它是目前医学影像界的工业标准S然该标准产生和发展于美国,但是目前它已经被世界上许多国家和地区所认同,世界上许多比较重要的医学影像设备的生产企业和厂商都表示了对DICOM标准的支持。在我国,DICOM标准是唯一被接受的国际标准。该标准以计算机工业化为基础,它可以使每个企业生产的不同数字医学影像设备之间传输和交换图像,它也对ISO-OSI和TCP/IP提供了很好的网络,DICOM标准的出现不仅有助于提高现代临床诊断与治疗的水平,而且对于那些与医学图像相关企业的经营效益的提高也有很大的帮助[35]。此外,鉴于当今科技发展的速度,DICOM标准被设计成一个多部分的文档结构,如果需要新增加或者删减部分内容时,只须在附录中阐述即可,这样只需要更改非常小的部分就能够完成非常强大的功能[36]。下面简要介绍一下各部分的主要内容_:第一部分,简介与综述(Introduction and Overview):简单介绍了 DICOM标难的概念、产生、设计原则以及组成,而且在该部分中也对第二部分到第十四部分做了简单的描述。第二部分,兼容性(Conformance):介绍了实现声明兼容性满足的要求以及兼容性声明的内容。要求厂商精确的描述他们产品的兼容性,每个用户都可以从制造商那里获得这样的一份声明。第三部分,信息对象定义(Information Object Definitions, IOD):规定了 DICOM 标准在使用时,通讯过程中信息对象的定义,定义了两种信息对象类普通型和符合型,其中普通信息对象类包含与它相对应的现实世界实体所固有的属性;符合信息对象类可包含非图像固有的属性。
………..
第3章Hadoop处理海量小文件存在的问题.......... 29
3.1 Hadoop处理海量小文件时存在的问题.......... 29
3.2 SequenceFile 格式详解.......... 31
3.3 日前Hadoop处理海量小文件的解决方案及不足.......... 34
3.4 本章小结.......... 36
第4章基于HDFS的海量医学影像存储系统的优化与实现.......... 37
4.1系统优化的基本思想和总体结构设计.......... 37
4.2 DICOM文件的合并与实现.......... 38
4.3 SequenceFile随机读取的改进与实现.......... 46
4.3.1小文件索引的设计.......... 46
4.3.2小文件索引的创建.......... 47
4.4 随机读取文 ..........49
4.5本章小结 ..........51
第5章实验与分析 ..........53
5.1实验目的 ..........53
5.2实验环境和数据.......... 53
5.3实验设计与测试.......... 54
5.4本章小结.......... 60
第5章实验与分析
5.1实验目的
本文主要研究的是利用Hadoop存储和处理海量的DICOM文件,但是由于DICOM文件通常都是数百KB的小文件,而Hadoop是为处理大数据而设计的,它默认数据块的大小为64MB,这样的话在处理海量小文件时性能很低,基于这点本文已经提出了相应的解决方案,因此本章的目的就是验证本文的设计方案对于小文件的各种访问性能与原HDFS系统相比的优势和变化。在HDFS系统的实际应用场景中,文件的批量读写是很常见的,由于HDFS在对小文件进行批量读写时性能很低,同时本文研究的DICOM文件就是一种小文件,因此为了解决这个问题本文采用了 SequenceFile技术对小文件进行合并。批量读写实验设计主要是为了验证本文的设计方案在对小文件进行批量读写的性能是否比直接批量读写小文件的性能有所提高。原HDFS批量读写DICOM文件实验设计:选取10000、20000、30000和40000个DICOM文件进行实验,分别直接从原HDFS系统中读取和写入,其中这些文件大小的分布情况是一样的,其实验测试的结果如图5-1所示:
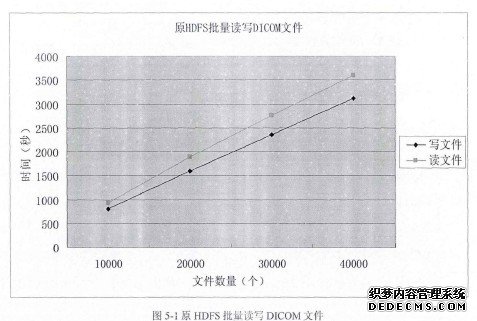
………
结论
本文在原HDFS的基础上进行了优化,实现了对DICOM文件的存储和处理。Hadoop是Apache的一个软件框架,它是针对大数据设计的,在处理大数据时能体现出很好的性能优势,而本文的主要研究对象DICOM文件一般只有数百KB,在Hadoop看来只是很小的文件,而Hadoop在处理海量小文件时有很多的不足,因此如何用Hadoop来存储和处理这些DICOM文件是本文的研究重点。本文的主要工作如下:
1.深入分析了 Hadoop架构的主要组件:HDFS系统和Map Reduce计算模型。重点分析了 HDFS读写文件的流程以及Map Reduce的工作机制;
2.分析了 Hadoop处理海量小文件的不足以及原因,详述了目前常用的两种解决方案:HAR归档技术以及Sequence File技术并且分析了这两种方法的不足;
3.研究了 DICOM文件格式,Sequence File文件格式以及Trie树的相关知识;
4.在原HDFS系统的基础上进行了优化,实现了对DICOM文件的存,和处理。优化的基本思想就是通过合并小文件以解决海量小文件元数据信息耗费Name Node节点服务器内存的问题,为此提出了基于时间的利用Sequence File技术对DICOM文件进行合并的方案,且形成了一种新的文件格式SF-DICOM格式。此外,为了提高Sequence FHe随机访问文件的效率,在Trie字典树的基础上,结合本文的实际情况设计了一种Trie树+二级索引的算法,建立了小文件即DICOM文件到合并后大文件之间的映射,从而有效的解决了系统随机访问的问题。
…………
参考文献(略)