第一章 绪论
1.1课题背景
随着信息时代的快速发展,诸多领域都在不断产生着大量的数据,比如金融、医疗、互联网等。为了从这些数据中获取有价值的信息,机器学习技术不断发展,分类问题是机器学习的基本任务之一[1-3]。分类算法通常是先利用训练集样本进行模型的训练,再对测试集样本进行分类判定。目前,己经有很多学者对分类问题进行了研究,并提出了很多优秀的算法,但分类问题仍是未来值得研究的方向。
当数据集的各个类别的样本比例不均衡时,则称之为不平衡数据集。若样本的分布极不均衡,甚至只有数量极少的少数类样本时,则可以称之为极端不平衡数据集。现有的分类算法通常假设数据集分布平衡,但是现实中的数据集大多存在标签分布不平衡的现象。当训练样本不同类别的比例相差较大时,会增加模型的学习难度。
对于不平衡数据集,分类模型在训练过程中往往会更关注多数类样本,忽视少数类样本,很容易将少数类样本错分为多数类,导致最终的分类结果不理想。但是少数类样本往往才是数据分布不平衡的分类任务中的研究重点。例如,在生物医学数据分析中,各种癌症数据样本是有限的,与正常非癌症病例相比,患病的人通常只是少数,因此,多数类与少数类的样本比例相差很大,这个比例可能为 100:1 甚至更高[4]。基于生活中人们对健康的重视,我们很有必要预测癌症的存在,或进一步尽可能准确地将不同类型的癌症作分类,从而在早期适当地进行预防或治疗。此外,在金融工程中,检测大量交易数据中的少量欺诈信用卡活动也是非常重要的[5]。所以在数据分布不平衡的分类任务中,如何提高算法对少数类样本的分类准确率,是需要解决的重要问题。
...................
1.2研究现状
针对分布不平衡数据的分类问题,主要从数据的重采样和分类算法的改进两个方面进行研究。分类算法的改进包括代价敏感学习和集成学习两个方面。当数据集出现极端不平衡现象时,也有学者会将不平衡分类问题转化为异常检测问题进行研究。
1、数据采样
对数据进行重采样是处理不平衡问题的常见方法。主要包括过采样方法、欠采样方法和综合采样方法。
(1)过采样方法
过采样方法通过合成新的少数类样本,减轻不平衡程度,从而提高整体分类性能。最简单的过采样方法仅对少数类样本随机复制或者简单的旋转,极易增加过拟合的可能性。为此,相关研究人员提出一些基于策略的过采样方法来合成新的少数类样本。SMOTE[6](Syntheticminority oversampling technique, SMOTE)过采样方法是最经典的过采样方法。该方法在少数类样本与其同类近邻样本之间做线性插值,生成无重复的新的少数类样本。由于 SMOTE 方法的随机性过大,无法控制合成样本的位置,学者们提出了 Borderline-SMOTE[7]、ADASYN[8](Adaptive Synthetic, ADASYN)等改进方法。近年来,有更多学者对过采样方法展开了研究。Zhu 等[9]通过引入样本选择权重,减小在选择近邻样本时的随机性;黄等[10]提出自适应变邻域过采样方法,将数据集划分为多个数据带,但是分类结果过于依赖于带数;Abdi 等[11]利用马氏距离寻找少数类近邻样本;Douzas 等[12]提出只对安全的少数类样本进行过采样,文中利用聚类算法对样本进行安全性评估,再利用 SMOTE 方法进行过采样生成新的数据。
(2)欠采样方法
欠采样方法通过删除多数类样本,从而使数据分布平衡。最简单的欠采样方法从数据样本中随机删除多数类样本,极易造成信息丢失。Oquab 等[13]通过随机选取与目标图像大小类似的背景图像块,减轻目标检测问题中的不平衡问题;方等[14]提出对数据样本多次进行随机欠采样,取平均结果,从而减小误差。随机欠采样方法可能造成重要信息的丢失,影响整体的分类性能。为了解决该问题,研究人员提出了一些基于给定策略的欠采样方法,最经典的包括 NCL 方法(Neighborhood Cleaning Rule, NCL)[15]和 Tome links 方法[16]等。Lin 等[17]提出了基于聚类的欠采样算法,基于 K 近邻规则,用聚类中心及其邻近样本表示多数类样本;吴等[18]提出了基于类重叠度不平衡数据欠采样的方法,将类重叠度作为依据,选出支持向量,从而进行分类。
...............................
第二章 相关背景知识介绍
2.1数据采样
在分类前,如果能利用重采样技术进行数据预处理,减轻数据的不平衡程度,分类器的性能就很可能得到改善。下面主要介绍包括针对少数类样本的过采样方法和针对多数类样本的欠采样方法。
2.1.1 过采样方法
过采样方法不对多数类样本进行任何处理, 只是增加少数类样本的数量来提高分类性能。下面介绍几个常见的过采样方法。
1、随机过采样方法
随机过采样方法是最简单的过采样方法。通过对已有少数类样本进行随机复制或者简单的旋转, 从而使少数类样本的数量增多,缓解不平衡程度。这种方法实现简单,但是容易导致分类算法过拟合。
2、SMOTE 方法
SMOTE 方法[6]是最经典的过采样方法。其基本思想是根据给定策略,将人工合成的少数类样本添加到数据集中。SMOTE 方法对于少数类样本集中的每个样本点,计算它到少数类样本集中所有样本的欧式距离,从而得到该样本点的 k 个最近邻样本。接着从样本点的 k 个最近邻样本中随机选择一个样本点,沿着该点与原样本点之间的线段做线性插值。
3、Borderline-SMOTE 方法
Borderline-SMOTE 方法[7]是对 SMOTE 方法的改进。考虑到位于少数类样本集和多数类样本集的边界的样本更容易被误分,因此它仅对边界附近的少数类样本进行过采样。对于每个少数类样本,计算其近邻样本。若一个少数类样本的多数类近邻样本数量大于其少数类近邻样本数量,则认为其位于边界附近。由于采样区域的选择是依照经验所定,所以Borderline-SMOTE 方法也具有局限性。
.........................
2.2集成学习
根据个体学习器的类型,集成学习可以分为同构集成和异构集成两种。同构集成是使用同一种分类器在原始训练集上生成多个训练子集上学习。当然,同构集成的基分类器虽然釆用相同的学习算法,但算法中使用的参数会随着训练子集的不同而改变。相对应地,异构集成是使用不同的个体学习器在训练集上进行学习。
典型的集成学习算法主要有 Bagging[43]族算法和 Boosting[39]族算法。
1、Boosting 算法
Boosting 算法又称提升法,是个体学习器之间存在强依赖关系,必须串行生成的序列化方法。其主要思想是将弱分类器提升为强学习器。首先从初始训练集训练出一个基学习器,接着根据基学习器的表现对训练样本分布进行调整,然后基于调整后的样本分布训练下一个基学习器,如此重复进行,直到基学习器数目达到事先指定的值,最后将这些基学习器加权结合。最经典的 Boosting 族算法是 Adaboost 算法[42]。
2、Bagging 算法
Bagging 算法又称套袋法,是个体学习器之间不存在强依赖关系,可同时生成的并行化方法。Bagging 算法基于自主采样法,首先采样出指定个数的采样集,然后基于每个采样集训练出一个基学习器,最后将这些基学习器进行结合。对分类任务进行结合时,通常采用简单投票法,对回归任务通常采用简单平均法。随机森林算法[49]是 Bagging 族的典型算法。

表 2.1 二分类任务的混淆矩阵
第三章 基于临时标记的 TempC-SSMOTE 过采样方法................ 14
3.1相关工作....................... 14
3.1.1 SMOTE 方法 ...................... 14
3.1.2 Safe-level-SMOTE 方法..................... 15
第四章 基于 CMAES 算法的集成学习方法 ........................... 24
4.1相关工作.............................. 24
4.1.1 集成学习 ............................ 24
4.1.2 CMAES 算法 .......................... 25
第五章 基于异常检测思想的特征处理方法 .......................... 34
5.1相关工作..................... 34
5.1.1 PCA 异常检测 .............................. 34
5.1.2 MCD 异常检测........................ 35
第五章 基于异常检测思想的特征处理方法
5.1基于异常检测思想的特征处理方法
异常检测算法大多采用无监督学习的方式进行分类。无监督学习的方法无法学习特征与标签之间的关系,因此其分类性能往往弱于监督学习。而特征提取是无监督学习的重要环节,通过不同的无监督学习方法可以从不同角度提取到数据的特征信息。因此本章提出采用异常检测的思想对数据进行特征提取,再结合分类器进行特征选择,这样既可以挖掘数据的内在信息,又能利用标签,学习到特征与标签之间的关系,从而提升分类性能。
本章实验选取的数据集由两部分组成。其中 smtp 数据集来源于 UCI 数据库,water2017、water2018、water2019 数据集则来源于 GECCO 会议(the Genetic and Evolutionary ComputationConference),是 2017-2019 年该会议举办的水质异常检测竞赛所使用的数据集。这几个水质数据集是由图林格·费尔南瓦(ThüringerFernwasserversorgung, TFW)公司提供的真实数据。TFW 是一家德国公共水务公司,它运营着 60 多个水坝和水库,2 个中央水处理厂以及 550公里的散水运输网络。为了监测水质,TFW 公司在整个配水系统的重要位置进行测量。数据集的具体信息如表 5.1 所示。
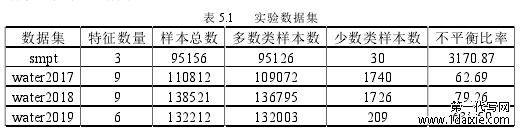
表 5.1 实验数据集
第六章 总结与展望
本文主要研究了面向不平衡数据集的分类任务,研究内容主要包括以下两个大的方面:
1、面向常规不平衡数据集
本文首先从数据采样的角度出发。基于 SMOTE 方法在合成新的少数类样本时,没有考虑到新生成的少数类样本的位置,本文引出一种改进的 Safe-Level-SMOTE 方法;针对过采样方法易引入噪声样本的问题,引入 TempC 方法来减小采样规模。并在此基础上,将Safe-Level-SMOTE 方法与 TempC 方法进行结合,提出一种基于临时标记的 TempC-SSMOTE过采样方法,用 Safe-Level-SMOTE 方法对临时标记的 C 类中的少数类样本进行过采样操作。这样既减轻了过采样算法易生成噪声样本的问题,又改善了分类困难区域的不平衡程度,从而提升算法的分类性能。
接着,本文从算法改进的角度出发,提出基于 CMAES 算法的集成学习方法。CMAES 集成学习方法是一种异质集成算法。在训练出基学习器后,用 CMAES 算法自适应训练个体学习器的组成权重从而达到最佳的分类性能。本文将 CMAES 集成学习方法与其他的传统分类方法和集成学习方法进行对比,证明了 CMAES 集成学习方法的优越性。
2、面向极端不平衡数据集
针对极端不平衡数据集分类任务,本文提出基于异常检测思想的特征处理方法。本文运用 PCA、LOF、HBOS、MCD 四种常见异常检测算法对数据特征进行处理,将异常检测算法中的异常评价值作为新的样本特征,实现对样本特征的扩充,从而从更多的角度挖掘养样本的异常信息。并利用贪心思想结合分类器,对样本特征进行组合,从而得到最优的组合特征。实验表明,基于异常检测思想处理后的数据特征可以明显提升分类器的分类性能。
参考文献(略)