目录
一、 稳健统计的基本思想及其产生和发展
二、 传统统计量
三、 几种稳健统计量的比较
参考文献
摘要
关键词
一、 稳健统计的基本思想及其产生和发展
统计学作为一套科学原理和技术,用于在即得信息既有限而又富于变化时,从中得出关于所感兴趣总体和过程的有关结论。也就是说,统计是从众多数据中挖掘有用的信息,然后得出有关这个领域的某些特征或结论,进而用以指导实践,来“创造”更好的数据的科学。然而,传统的用以描述数据或数据分布特征的统计量在许多情况下都不具有很强的代表性,使得分析结果与实际不符,据此制定相关政策用于指导实践时,必定会产生不利于社会经济发展的情况。存在这一问题的原因在于,传统的统计方法对所研究问题数据服从正态分布的假定有着很强的依赖性,当真正的数据并不是或并不完全服从正态分布时,如果还按照传统的统计方法来描述我们所要研究的问题,就必定会产生偏差,甚至有时这种偏差是非常大的。然而从对经济、社会以及自然科学各种现象的实际问题和数据分析中发现,正态分布的基本假定和人们面对的实际问题与数据是否在所有场合或大多数场合相吻合是一个首先要考虑的基本问题。即使是一种正态分布,但是否是理想化的正态分布也是值得怀疑的。研究者对很多数据分布形态的研究表明,正态分布是一种理论上的分布,实际的数据至多是近似的正态分布,具体表现为正态分布有一定的偏斜。而这种偏斜可能会对统计量的稳健性即耐抗性产生致命的影响。如果某种统计方法对偏离正态假定的分布十分敏感,就不是稳健的统计方法。因此也就需要对传统的统计方法进行稳健化,需要有更能够比较准确地处理实际问题的方法的出现。
事实上稳健统计方法的思想发展史是与经典统计方法的思想发展史交织在一起的。早在十九世纪初高斯(Gauss)提出正态分布与最小二乘方法的时候,就有了稳健性思想的萌芽。当时就有学者发现,一些实际样本并不服从正态分布,其大误差的频率比正态分布应有的频率要高,即观察数据中有一定量的离群值。还有人提出,由高斯的最小二乘估计得到的样本平均值,并非估计位置参数唯一的普遍方法。例如,当时法国有些省份在计算粮食平均产量时,把连续20年的纪录中最高的和最低的产量去掉,再对其余18年的产量求平均。这种方法在20世纪60年代被Tukey称作切尾均值( trimmedmean)。19世纪中后期,有人提出了一些剔除异常值的方法及描述误差分布的非正态律。20世纪以来,又先后有学者观察到某些常用方法对偏离正态假定十分敏感,因此也提出了一些相当稳健的方法。但是由于稳健统计本身的复杂性,以及计算技术的限制,直到上个世纪50年代为止,稳健统计一直都在经历着长达一个半世纪的酝酿阶段。1953年,G.E.P.Box首次引入了“稳健性”这一概念。然而稳健统计受到统计学界普遍关注还是20世纪60年代初从J.W.Tukey开始的。Tukey从40年代起反复研究了一些经典统计方法的不稳健性,重新确定了切尾均值和平均绝对离差(mean absolute deviation)等估计方法的良好稳健性。随后, P. J. Huber于1964年发表了以“位置参数的稳健估计”为题的开创性论文,可以说标志着稳健统计学系统性研究的开端。1973年他又将其推广到多参数回归模型的参数估计等方面。F.R.Hampel在70年代初,给出了稳健性的一个较为严格的定义,并提出了刻画稳健性的两个重要概念:崩溃点和影响曲线。加之许多其他学者的努力,使稳健统计学逐渐发展成为数理统计学的一个活跃的分支。1981年, P. J.Huber又发表了一本系统论述稳健统计学的专著《Robuststatistics》,在该书中Huber正式给出稳健统计的定义,即:一种稳健统计方法应该能够很好而且合理地处理假定模型;当模型有少许偏离时,其结果也应该只遭到少许破坏;当模型有较大的偏离时,结果也不应该遭到破坏性的影响。至此,稳健统计理论趋于成熟。由于稳健统计方法不受实际数据是否服从正态分布条件的束缚,与传统的统计方法相比,具有更强的抵抗异常值影响的能力,更能够反映实际情况,所以它一问世就有着很强的生命力,并逐渐地被广泛应用于医学、生物学、化学以及地质学等领域,成为人们处理各种问题的重要思想和工具。
稳健统计的内容非常广泛,任何涉及到与实际问题和假定条件有偏离有关的传统统计方法中,都会有稳健统计滋生的土壤,都会有有待于对传统统计方法进一步完善的空间和必要。本文将主要分析几种代表总体平均水平的稳健统计量的稳健性,并与传统的统计量如样本平均数等进行比较,从而揭示稳健统计量的优势所在。由于篇幅所限,对稳健统计的其他方面的讨论不在本文范围之内。
二、 传统统计量
人们都会感觉官方公布的人均收入或人均工资之类的指标明显偏高。进一步研究发现,抛开统计误差和统计口径不说,对人均收入指标主观上认为偏高的主要原因在于收入分布是一种偏态的分布,而且随着贫富差异原因的增多,偏态有日益严重的态势。同时收入分布中存在着异常极端的离群大值,也会导致收入平均值的不正常上升。举一个极端一点的例子,如果收入数据中有一个值趋于无穷大,不管是由于操作失误还是实际情况的真实反映,据此计算出来的平均收入也会趋于无穷大,由此可见,运用非常普遍的平均数丝毫不具有抵御离群值的能力。这也就意味着在正态假定下性能表现非常良好的平均数,当实际数据并不是呈正态分布时所表现出的代表性不强的缺陷。这就引发人们去思考其他的统计量,要求这些统计量满足以下两个条件:第一,当实际分布未知或虽然已知但不是正态分布时,这样的统计量应该能够比较好地描述所研究现象的实际情况;第二,当数据中存在正常的或是非正常的离群值时,这样的统计量不会偏离实际情况太远,也即不会因为离群值的存在而对我们所要说明的问题以及想要得出的结论造成灾害性的影响。满足上述两点的统计量就是稳健的统计量。与平均数相比,中位数就是相当稳健的,因为再极端的数据都不会影响到中位数本身的变化。因此有人建议用中位数来代表所研究现象的一般水平会更具代表性。然而中位数也仅仅是基于排序以后的数据,而且对数据中间部分的舍入和分组也比较敏感,同时对总体平均水平的度量效率不是很高。
切尾均值是对均值的一种变通方法。我们知道,均值对异常值或离群值非常敏感,它会由于数据集合中的一个或多个异常值的出现而失真。在这种情况下,离群值会使均值偏向自己的一方以寻找平衡点,因而也就歪曲了均值作为平均水平度量的意义。这时就需要对均值的计算方法进行适当的变通,使之较为稳健。通常用到的就是切尾均值,其做法是去掉最大的和最小的数据,然后对其余的作平均。例如,切尾率为5%的切尾均值就是指去掉5%的最大值和5%的最小值后对剩余90%的数据作平均所得到的结果。因此,样本均值可以看作是0%的切尾均值,即切掉0% (也就是不对原始数据进行截取)的数据之后剩余数据的平均值;而中位数则可以认为是切尾率随样本容量n变化的切尾均值,切尾率是1/2-1/2n。所以当样本容量趋于无穷时,切尾率的极限为1/2即50%,也就是说,中位数大体上相当于50%的切尾均值,即左右各切大约50%剩下的数或经简单处理之后所得的数即为中位数。在实际运用当中,根据离群值的分布情况及数量来确定切尾率的大小,从而更准确地反映数据总体的平均水平。同时,由于离群值有时能够反映出总体的一些新亮点,因此对切掉的离群值进行单独分析也是很有意义的。
三、 几种稳健统计量的比较
从数理角度分析,许多统计量都是通过极小化某一目标函数而得到的结果。例如我们所熟悉的样

到,基于残差平方目标函数的样本平均值的统计量对于离群值过于敏感,即由于经过平方,使得数据分布的尾部有太大的权数;而基于绝对残差目标函数的样本中位数虽然克服了样本平均值对离群值敏感的缺陷,但却对数据的中间估计值太敏感。于是,Huber(1964)提出了一种新的目标函数,作为样本平均值和样本中位数的折中。这个目标函数就是
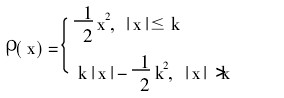
极小化上述目标函数的解就是HuberM统计量。样本中位数和平均数分别是HuberM统计量的极端情况, k称作细调参数,它决定着Huber统计量的性质。在实际运用中选择适当的k,能给统计量在某个范围上合理的性能表现。k越小,Huber统计量越接近于样本中位数,即对离群值的抵抗能力就越强,反之,就越接近于样本平均值。Huber统计量是一种比较容易计算的稳健统计量,是对样本平均值的稳健性的提高和改善。但是与下面三种更稳健的M统计量相比较,Huber统计量的稳健性有时也不能够满足实际需要。
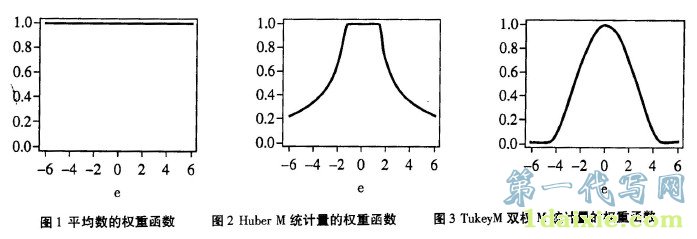
根据M统计量ψ函数(即目标函数的导数)的形状,人们把Huber统计量称作单调的M统计量,另外三种比较常见的M统计量:图基(Tukey)双权M统计量、汉佩尔(Hampel)回降M统计量和安德鲁斯(Andrews)正弦波统计量都是回降统计量。也就是说,HuberM统计量的ψ函数是单调递增的,而后面三种M统计量的ψ函数最终都要回到水平轴,其函数形式均比较复杂,这里从略。需要强调指出的是,M统计量之所以较平均数稳健,是因为相对于平均数对所有观察值都赋权数以1的情形, M统计量最终的目标是根据观察值离数据分布中心的远近而赋大小不等的权数,即观测值距离数据分布中心越远,赋予它的权数就越小,反之就越大。从而提高统计量的全局效率和整体耐抗性。不同的M统计量具有不同的加权体系。下面是平均数和两种M统计量的权重函数图,从中可以很清楚地看出不同统计量的权重分布情况,HampelM统计量和An-drews正弦波M估计量的权重函数的形状与Tukey双权M统计量大体上类似,都是中间部分权数较大,以后逐渐递减,到两侧的某一点减小到零。所不同的是,如同HuberM统计量中的k一样,不同的统计量具有不同的细调参数,从而也决定了权重函数走势变化的分界点。
下表是笔者利用SPSS软件对天津市近十二年的居民实际支出原始数据计算的四种M统计量(为节省篇幅,只列出每隔一年共六年的计算结果),并列出了平均支出和中位数支出以供比较。
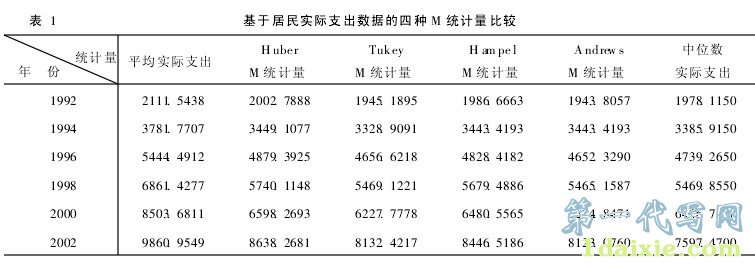
通过上表对六种统计量的比较,我们发现,四种M统计量均低于平均实际支出,而与中位数实际支出的大小关系不固定。由于实际支出数据中有一定量的离群值存在,所以平均实际支出是对实际数据的一种偏高估计,这是毫无疑问的;又由于中位数附近可能出现的分布离散性,使得中位数在整体上是对实际数据的一种偏低估计。而M统计量反映了支出数据主体部分的更多信息,因而能够更准确地体现实际支出的一般水平。四种M统计量中, Hu-berM统计量更容易受极端值的影响,在表1中也可以看出, HuberM统计量与平均实际支出最为接近,因此如果我们追求的是正态分布附近的较高效率而牺牲在较重尾分布的效率,则选用HuberM统计量,而如果是为了全局效率和耐抗性,则更适宜用其他三种M统计量。
由以上分析可知,运用非常广泛的样本平均数,虽然有其计算简单的优点,但却在很多情况下不能够很好地代表我们所研究现象总体的平均水平。因此,对更加稳健的统计量的重视和应用,无论是对数据使用者还是对政策的制定者,都有其不可忽视的重要意义。
[参考文献]
[1] (美)R•L•奥特,M•朗格内克.统计学方法与数据分析引论[M].北京:科学出版社, 2003.
[2] (美)David C Hoaglin等.探索性数据分析[M].北京:中国统计出版社, 1998.
[3] 孙宪华.稳健统计在经济指代写毕业论文标中的应用及其启示[J].现代财经, 2003, (12).
[4] 孙宪华,郭亚帆.居民实际支出指标的稳健性分析[J].天津师范大学学报, 2005, (1).
[摘 要]稳健统计作为统计学的一个较为活跃的研究领域,是对传统统计方法的完善和补充,其中最为简单和通俗易懂的是统计量的稳健性。本文对几种常用的统计量进行深入地剖析,进而揭示其稳健性的不足,同时给出几种稳健统计量,并与传统的统计量进行比较,通过比较来展现稳健统计量的优势及其应用价值。
[关键词]稳健统计;切尾均值;M统计量